There’s a cute quip: statistics don’t lie.
There’s an accurate quip: statistics don’t lie, given a well-trained model and a large enough sample.
With statistics on your side, you can be 99% sure that you’re right. Unfortunately, people who are 99% sure are wrong 40% of the time.
I was recently thinking about the way Hindi and Urdu represent possession. The language doesn’t have a verb “to have,” and so uses three different constructions depending on the type of possession and the object possessed.
Long story short, if the possessed object is physical and alienable (possession is impermanent), you use ke pās, or “near.”
Rajesh ke pās ek kitāb hai
Rajesh.GEN-near one book is
“Rajesh has a book.”
If it’s nonphysical and alienable, you use ko, or “to.”
Rajesh ko ek bukhār hai
Rajesh-to one fever is
“Rajesh has a fever.”
Finally, if it’s inalienable (things that always belong to you, like body parts or relatives), you use a copula construction.
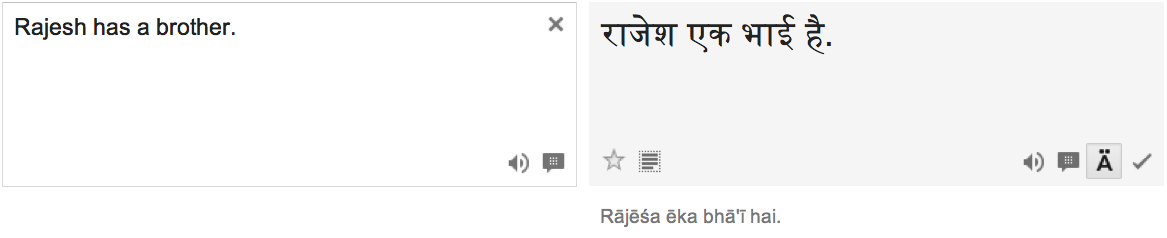
Rajesh kā bhāī hai
Rajesh-of brother is
“Rajesh has a brother.”
Now, let’s say you were trying to learn Hindi using the state-of-the-art machine translator, Google Translate. How would it treat you when it comes to possession?
The answer, it turns out, is not so well.

Input: “Rajesh has a fever.” Output: “Rajesh is a fever.”

Input: “Rajesh has a book.” Output: “Rajesh is a book.”
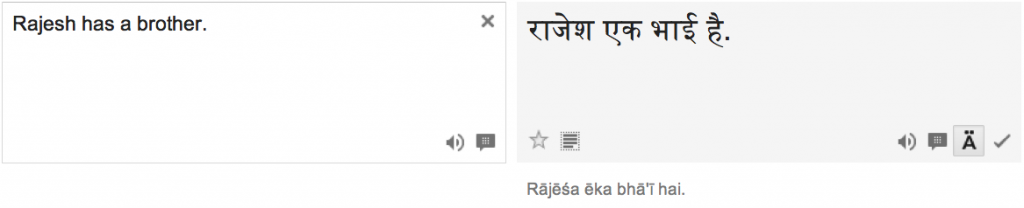
Input: “Rajesh has a brother.” Output: “Rajesh is a brother.”
Clearly, Google Translate is missing something here–the entirety of the possession entailed by the English “have.” But watch what happens below:
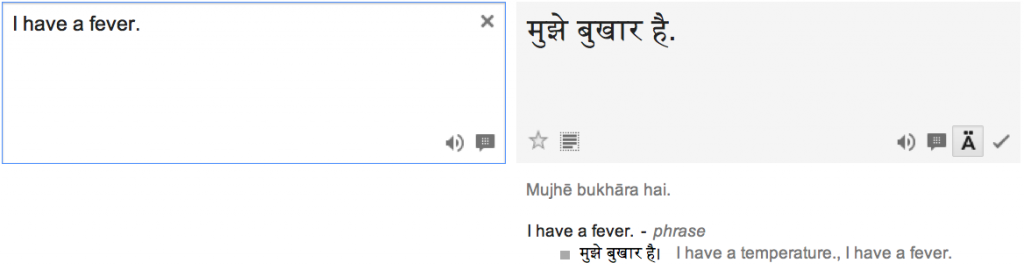
Input: “I have a fever.” Output: “I have a fever.”
Yay! So maybe it works with “I”, but not a third person?

Input: “I have a book.” Output: “I is a book.”
Okay, maybe not?
We get a clue from “I have a fever.” Notice how below the translation, it notes it as a phrase? “I have a fever” is a common enough phrase that it’s showed up in some Hindi-English corpus that Google Translate trained over, so it “knows” the phrase “I have a fever,” and that it corresponds to mujhe ek bukhār hai (mujhe is a contraction of mujhko, “to me”).
It turns out the ko construction is used in a number of common phrases regarding feeling (including sickness) and emotion:
mujhe is kitāb se pasaṃd hai = “I like this book”
mujhe tumse pyār hai = “I love you”
All these kinds of phrases are common enough that Google Translate has surely seen them in a corpus. It can scan along its input, find familiar phrases and then replace them with their equivalents: “I have a fever,” she said becomes “X,” she said and since the translator knows that there’s a high probability that X as a block translates to mujhe ek bukhār hai, it just swaps it in, and is left with “mujhe ek bukhār hai,” she said, and only two words left to translate. This is called “phrase-based” translation, which Google Translate uses to take a lot of work out of its translation task, breaking inputs up not into the individual words, but into bigger chunks that it can translate wholesale.
Which brings us back to the “Rajesh is a book” problem. “Rajesh has a book” is not a common phrase that the translator algorithm can just swap in, so it tries breaking it apart into chunks: maybe “Rajesh” and “has a book.” The name goes through all right, but as we’ve seen, “has a book” is not a phrase that has an easy Hindi equivalent in isolation. You have to do some stuff to the possessor as well, which is no longer part of this chunk. The same thing happens if you split it differently: say, “Rajesh has” and “a book.” It can translate “a book” just fine, but “Rajesh has” is now a problem, because it can’t translate “has” without knowing what is possessed, and “a book” is outside the chunk being examined.
What it might do is break it down until it gets translatable portions, and so ends up with “Rajesh”, “has”, and “a book.”
Rajesh ⟶ Rajesh
a book ⟶ ek kitāb
has ⟶ NULL
“has” goes to NULL, because there’s no direct translation. It might look in its knowledge and see a lot of “has” sentences in English that end in hai in Hindi. Knowing that Hindi sentences often end in the verb (tree-based translation), it seems like there might be reason to translate “has” as hai, which it does, though perhaps not very confidently. has ⟶ hai, and Rajesh is a book.
But what if we were to invoke some kind of semantic category? Turn “a book” into, say ALIENABLE PHYSICAL OBJECT. Seeing that, we could train the translator to know that “has ALIENABLE PHYSOBJ” should translate to “ke pās ALIENABLE PHYSOBJ hai.” Suddenly “has a book” has a distinct translation, because we know what kind of thing a book is. The process would then look something like this:
a book ⟶ ALIENABLE PHYSOBJ (store “a book” somewhere so you can get it back)
has a book ⟶ has ALIENABLE PHYSOBJ
Rajesh ⟶ Rajesh
has ALIENABLE PHYSOBJ ⟶ ke pās ALIENABLE PHYSOBJ hai
ke pās ALIENABLE PHYSOBJ ⟶ ke pās a book hai
a book ⟶ ek kitāb
It takes a little longer and you have to have this extra semantic layer in the middle, but you get it right in the end.
Basically, the machine currently fails at this task because we haven’t cracked the question of meaning yet. The computer doesn’t know that a book is a physical object that can be given away or that a fever is an impermanent affliction or that your relative will always be your relative. That requires a human to go in there and annotate those things as such. The holy grail of machine translation is to be high quality (correct), general domain (you can talk about anything), and machine exclusive (you don’t need a person to either format things before it’s translated, or to fix it up afterwards). So far, we can usually hit two out of three with the most advanced computational linguistic techniques. Statistics do very well in some cases, especially between languages where there are very large parallel corpora that allow things to be restricted to a big but closed set of phrases and word chunks. However, this is not a general solution, and has to be tweaked for each language pair, and we usually still have to have a human in the loop to come in and clean things up, so that poor Rajesh isn’t a book.
But we’re working on that.